Best Data Handling and Data Management Difference with their Meaning and Option to which one very important. Technology and Innovation have changed the world in the new couple of years. With the appearance of innovation, each area is expanding on the web. It has made a requirement for huge space to store a particularly gigantic measure of data on the web. In this way, data focuses are giving code vaults to putting away data safely.
Here is the article to explain, What is the best difference between Data Handling and Data Management? with Meaning and Option.
Datacenter organizations like Equinix, Digital Realty, Verizon, Cyxtera Technologies, GitHub, and Microsoft are building various frameworks to satisfy the developing need for data stockpiling stages. Also, With the assistance of these code vaults, an individual can store photos, recordings, archives, some secret data, or assets safe and forestall the danger of robbery.
As we probably are aware, putting away data online has its benefits and drawbacks. On one side, it is making our work life simple, helpful, and bother-free, and on the opposite side, it is conveying us defenseless against digital intimidations. Subsequently, it is urgent to understand the difference between data handling and data management. Additionally, an individual can decide on data investigation projects to more readily understand data and how it can profit one’s vocation.
What is the best difference between data handling vs data management?
Data Handling includes putting away or discarding data in a got way. It has to do with the passage and capacity of data that can be recovered later. This assortment, stockpiling, and recovery of data should be possible both by manual and robotized measures. The data is critical to the organizations since it can introduce a ton of data about the usefulness of an association.
This is the place where Data Management becomes possibly the most important factor, it manages the use of recently gathered and arranged data to examine and introduce experiences that can represent the deciding moment of a firm. These organizations use data investigation for this reason, and since data of this sort are produced an immense volume, consequently, large data assumes a critical part here.
Bits of knowledge into Huge or Big Data:
Enormous Data is the assortment of data in a huge volume. Also, It is one of the types of data that is developing each day and consistently. Social Data, Machine Data, and Transactional Data add to the age of Big Data. Large Data is tremendous to such an extent that it can’t be put away through any customary data stockpiling apparatus.
Also, handling Big Data with regular data putting away devices with effectiveness is a serious complex interaction. Businesses are utilizing Big Data to acquire data about clients, which they use in focusing on possible clients. The 5 V’s-Volume, Velocity, Variety, Veracity, and Value is behind making Big Data a gigantic business for ventures throughout the planet.
Recognition in Data Analytics Co-operation program and its advantages:
It is a one-year program zeroing in on giving fundamental information needed in examining data; and, improving dynamic abilities for maintaining a business effectively. After finishing the course, an understudy is offered the jobs of Data Analyst, Data Mining Analyst, and Business Analyst. On the off chance that you are planned to acquire uncommon abilities and searching for better-paying positions; apply to the program from the main management school in Off-line and Online today!
Best Data Handling and Data Management Difference with their Meaning and Option; Image from Pixabay.
Companies using data warehousing and its effects, How many Types of Data Warehousing? What are the benefits of using data warehousing? The term data warehouse or data warehousing was first coined by Bill Inmon in the year 1990 which was defined as a “warehouse which is subject-oriented, integrated, time variant and non-volatile collection of data in support of management’s decision-making process”. When referring to data warehousing as subject-oriented, it simply means that the process is giving information about a particular subject rather than the details regarding the on-going operations of the company. It is a blend of technologies and components which allows the strategic use of data. You are read and studying to learn, What do you think of Data Warehousing? Download PDF.
A data warehousing is a technique for collecting and managing data from varied sources to provide meaningful business insights. What do you think of Data Warehousing? Download PDF.
It is electronic storage of a large amount of information by a business which is designed for query and analysis instead of transaction processing. It is a process of transforming data into information and making it available to users in a timely manner to make a difference. Moreover, when data warehousing was referred to as integrated it means that the data or information which are gathered from a number of sources are then all gathered to synthesize a coherent whole.
On the other hand, data warehousing being time variant simply means that the data available were identified during a particular period. Lastly, data warehousing as being non-volatile means that the data is stable and when a new data is added to the system, the old data are never removed, instead they just remain there and this enables the organization to be able to give the management consistency in their business. In the existence of modern times with the advent of technological advancements inevitably affecting the businesses in major ways, there has also been a development and emergence of new measures, practices, and techniques which used technology to be able to provide an unwavering solution to the problems in the organization with regards to the level and kind of information that the organization needs to be able to survive and prosper amidst the increasing competition in the market.
Undeniably, one of this techniques and practices refers to the emergence of data warehousing as a tool for helping today’s businesses to be able to manage competition and the turbulent economic condition. The birth f the concept of data warehousing can be contributed to various researches and studies which were conducted in the past to provide various organizations with the means of getting information in a manner which is efficient, effective, and flexible. The data warehousing which is known today among the corporate practice is not what it was when it started almost two decades ago. The practice of data warehousing nowadays is a result of the experiences and technologies in the last twenty years. Bill Inmon and Ralph Kimball are two of the heavyweights when it comes to data warehousing.
However, although their names are known in this field, these two scholars have two varying views with regards to data warehousing. The paradigm which was illustrated by Inmon holds that the data warehouse forms only a part of the general business intelligence system. On the other hand, the paradigm of Kimball assumes that the data warehouse is a conglomerate of all the data in the organization.
Other researchers assume that there is no right or wrong theories among the two assumptions from the two heavy weighs in data warehousing. However, most of them support the notion of Kimball’s paradigm. They believe that most data warehouses started only as efforts from various departments starting with what they call as data marts until they develop and evolve to become a data warehouse. Furthermore, data warehousing has been heralded as one of the sustainable solutions to management information and dilemma and such also provide the organization and environment which entails various benefits if they are practiced in the right way and if the perspectives are directed towards the right goal.
The process of data warehousing is said to have the intention of providing an architectural model which can best provide an illustration of the flow data from the systems regarding the operation of the decision support environments. However, according to the same author, one problem stems down from the data warehousing technique – that is such a system is said to be too expensive to be affordable for some organizations or businesses.
It is undeniable that data warehousing continues to attract interest, it is also undeniable that many projects are failing to deliver the expectations from what they are supposed to deliver and they still prove to be too high of accost to be handled by some businesses. However, to be able to justify this relatively high cost, it has been said that organizations should look at the long-term benefit of the warehouse rather than simply looking at the short-term benefits that such an offer. Moreover, data warehousing is also said to be designed to be able to support ad-hoc data analysis, inquiry and reporting by end-users, without programmers, interactively and online.
There are some key factors which can make the data warehousing practice a success among different organizations. One of the key ingredients to the success of the practice is to make the management, especially the higher management, aware and conscious of all the benefits which this tool entails and what can data warehousing do to improve the performance of the business.
Another key to the success of data warehousing is choosing the right people to make it happen. By choosing the right people, the contribution of individual minds should be recognized to form a synthesis and a greater whole. Training strategy, the right structure or architecture, a sustainable mission statement, showing early benefits, ensuring scalability, understanding how important is the quality of data and using only proven and effective methodology are some of the other key ingredients to make data warehousing a successful practice, Data Warehousing file Download in PDF.
Why needs Data warehousing?
The data warehousing is needed for all types of these users like:
If the user wants fast performance on a huge amount of data which is a necessity for reports, grids or charts, then Data warehouse proves useful.
Decision makers who rely on the mass amount of data.
It is also used by the people who want simple technology to access the data.
It also essential for those people who want a systematic approach to making decisions.
The data warehouse is a first step If you want to discover ‘hidden patterns’ of data-flows and groupings.
Users who use customized, complex processes to obtain information from multiple data sources.
The Companies using data warehousing and its effects.
An example of a known company which uses data warehousing is WalMart. Being the world’s largest retailer, many say that the company should be also the organization with the largest data warehouse which is going to serve as the database of its inventory and all transactions related to their business performance. The data warehousing also has a big implication on the business of WalMart.
According to the management of the world’s largest retailer, more than any other purpose, their data warehouse is helping them to be able to make decision support systems between the company and its various suppliers. Aside from that, another implication of data warehousing on WalMart is that it enables the suppliers to be able to access a large amount of online information and data which will be helpful with their suppliers in terms of improving their operations.
One example of companies using and reaping the benefits of adapt warehousing will be various pharmaceutical companies, or on a larger scale, the general healthcare industry. For most of the pharmaceutical businesses which are under operation, they were able to acknowledge the fact that they lack a sustainable focus on their promotional practices, resulting in diffused sales efforts. With that, they regard that data warehousing technique has a big implication in their business because they regard such as the best medicine and remedy for the aforementioned problem.
They are even using data warehousing to be able to attain a sustainable competitive edge against other businesses in the industry. In the case of pharmaceutical companies, it has an implication also in the marketing department. Data warehousing helps the marketing department, through various information contained, to come up with promotional and marketing activities which can yield the maximum results. Moreover, data warehousing also has an implication on the human resources department of the organizations because they can also help in the effective allocation of people and resources.
How many Types of Data Warehousing?
There are three main types of Data Warehousing are:
Enterprise Data Warehousing: Enterprise Data Warehouse is a centralized warehouse. It provides decision support service across the enterprise. It offers a unified approach to organizing and representing data. It also provides the ability to classify data according to the subject and give access according to those divisions.
Operational Data Store: Operational Data Store, which is also called ODS, are nothing but data store required when neither Data warehouse nor OLTP systems support organizations reporting needs. In ODS, Data warehouse is refreshed in real time. Hence, it is widely preferred for routine activities like storing records of the Employees.
Data Mart: A data mart is a subset of the data warehouse. It specially designed for a particular line of business, such as sales, finance, sales or finance. In an independent data mart, data can collect directly from sources.
What are the benefits of using data warehousing?
Some of the benefits of data warehousing that it offers include the fact that it has a relative orientation on the subject area, it has the ability to provide an integration of data which were retrieved from diverse and multiple sources, it allows data analysis from time to time, it adds ad hoc inquiry and reporting, it provides decision makers with the capabilities to analyze, it relieves the IT from information development.
It has the ability to provide better performance for complex analytical queries, it relieves the burden of processing databases which are based on transactions, it allows a planning process that is perpetual and continuous, and lastly, it converts corporate data to make them strategic information which can help them in planning for a better performance of the organization.
Another benefit of data warehousing is that it enables and it helps different organizations in the strategic decision making resulting into the formulation of strategic decisions which are geared towards enabling a better business performance and yielding better results.
It can be assumed that most data warehousing practices are not intended for strategic decision making because they are normally used for post-monitoring of decisions regarding how effective they are. Nonetheless, it should not be also disregarded that data warehousing, can also be sued for strategic decision making and can be used profitably.
Another benefit of data warehousing is that it enables the user to have unlimited access to a relatively very large amount of enterprise information which can be used to potentially solve a large number of enterprise problems which can even be used to increase the profitability of the company. A very well-designed data warehouse can yield a greater return-on-investment with unlimited benefits had the ability to better assess the risks associated with the organization. Fully read on PDF file and download.
Learn and Understand, What to TAKE During the Job Analysis?
Gathering job-related information involves lots of efforts and time. The process may become cumbersome if the main objective of it is not known. Any information can be gathered and recorded but may be hazardous for health and finances of an organization if it is not known what is required and why. Also Learned, Meaning and Definition, What to TAKE During the Job Analysis?
Before starting to conduct a job analysis process, it is very necessary to decide what type of content or information is to be collected and why. The purpose of this process may range from uncovering hidden dangers to the organization or creating a right job-person fit, establishing effective hiring practices, analyzing training needs, evaluating a job, analyzing the performance of an employee, setting organizational standards and so on. Each one of these objectives requires the different type of information or content.
While gathering job-related content, a job analyst or the dedicated person should know the purpose of the action and try to collect data as accurate as possible. Though the data collected is later on divided into two sets – job description and job specification but the information falls in three different categories during the process of analyzing a specific job – job content, job context and job requirements. Also Study, Explain Advantages and Disadvantages of Job Analysis!
#Job Analysis and Data Collection:
Job analysis involves collecting information on characteristics that differentiate jobs. The following factors help make distinctions between jobs:
Knowledge, skills, and abilities (KSAs) needed.
Work activities and behaviors.
Interactions with others (internal and external).
Performance standards.
Financial budgeting and impact.
Machines and equipment used.
Working conditions.
Supervision provided and received.
Grouping jobs with related functions are helpful in the job analysis process by identifying the job family, job duties and tasks of related work.
The following provides an example of how an organization may group related jobs:
Job family: Grouping of related jobs with broadly similar content.
Job. Group of tasks, duties, and responsibilities an individual performs that make up his or her total work assignment.
Task:A specific statement of what a person does, with similar tasks grouped into a task dimension (i.e., a classification system).
A technical service job family, for example, could be identified as follows:
Job Family:Technical Service.
Job: Technical service representative.
Task: Provides technical support to customers by telephone.
What to Take?
Job Content.
Job Context, and.
Job Requirements.
#Job Content:
It contains information about various job activities included in a specific job. It is a detailed account of actions which an employee needs to perform during his tenure. The following information needs to be taken by a job analyst:
Duties of an employee,
What actually an employee does,
Machines, tools, and pieces of equipment to be used while performing a specific job,
Additional tasks involved in a job,
Desired output level (What is expected of an employee?),
Type of training required.
The content depends upon the type of job in a particular division or department. For example, job content of a factory-line worker would be entirely different from that of a marketing executive or HR personnel.
#Job Context:
Job context refers to the situation or condition under which an employee performs a particular job. The information takes will include:
Working Conditions
Risks involved
Whom to report
Who all will report to him or her
Hazards
Physical and mental demands
Judgment
Well like job content, data collected under this category are also subject to change according to the type of job in a specific division or department.
#Job Requirements:
These include basic but specific requirements which make a candidate eligible for a particular job. The taking of data includes:
Knowledge of basic information required to perform a job successfully.
Specific skills such as communication skills, IT skills, operational skills, motor skills, processing skills and so on.
Personal ability including aptitude, reasoning, manipulative abilities, handling sudden and unexpected situations, problem-solving ability, mathematical abilities and so on.
Educational Qualifications including degree, diploma, certification or license.
Personal Characteristics such as the ability to adapt to different environment, endurance, willingness, work ethic, eagerness to learn and understand things, behavior towards colleagues, subordinates, and seniors, sense of belongingness to the organization, etc.
For different jobs, the parameters would be different. They depend upon the type of job, designation, compensation grade and responsibilities and risks involved in a job.
An arrangement of networked computers in which data processing capabilities are spread across the network. In DDP, specific jobs are performed by specialized computers which may be far removed from the user and/or from other such computers. This arrangement is in contrast to ‘centralized’ computing in which several client computers share the same server (usually a mini or mainframe computer) or a cluster of servers. DDP provides greater scalability, but also requires more network administration resources.
Understanding of Distributed Data Processing (DDP)
Distributed database system technology is the union of what appear to be two diametrically opposed approaches to data processing: database system and computer network technologies. The database system has taken us from a paradigm of data processing in which each application defined and maintained its own data to one in which the data is defined and administered centrally. This new orientation results in data independence, whereby the application programs are immune to changes in the logical or physical organization of the data. One of the major motivations behind the use of database systems is the desire to integrate the operation data of an enterprise and to provide centralized, thus controlled access to that data. The technology of computer networks, on the other hand, promotes a mode of that work that goes against all centralization efforts. At first glance, it might be difficult to understand how these two contrasting approaches can possibly be synthesized to produce a technology that is more powerful and more promising than either one alone. The key to this understanding is the realization that the most important objective of the database technology is integration, not centralization. It is important to realize that either one of these terms does not necessarily imply the other. It is possible to achieve integration with centralization and that is exactly what at distributed database technology attempts to achieve.
The term distributed processing is probably the most used term in computer science for the last couple of years. It has been used to refer to such diverse system as multiprocessing systems, distributed data processing, and computer networks. Here are some of the other term that has been synonymous with distributed processing distributed/multi-computers, satellite processing /satellite computers, back-end processing, dedicated/special-purpose computers, time-shared systems and functionally modular system.
Obviously, some degree of the distributed processing goes on in any computer system, ever on single-processor computers, starting with the second-generation computers, the central processing. However, it should be quite clear that what we would like to refer to as distributed processing, or distributed computing has nothing to do with this form of distribution of the function of function in a single-processor computer system. Web Developer’s Workflow Become Much Easier with this Innovative Gadgets.
A term that has caused so much confusion is obviously quite difficult to define precisely. The working definition we use for a distributed computing systems states that it is a number of autonomous processing elements that are interconnected by a computer network and that cooperate in performing their assigned tasks. The processing elements referred to in this definition is a computing device that can execute a program on its own.
One fundamental question that needs to be asked is: Distributed is one thing that might be distributed is that processing logic. In fact, the definition of a distributed computing computer system give above implicitly assumes that the processing logic or processing elements are distributed. Another possible distribution is according to function. Various functions of a computer system could be delegated to various pieces of hardware sites. Finally, control can be distributed. The control of execution of various task might be distributed instead of being performed by one computer systems, from the view of distributed instead of being the system, these modes of distribution are all necessary and important. Strategic Role of e-HR (Electronic Human Resource).
A distributed computing system can be classified with respect to a number of criteria. Some of these criteria are as follows: degree of coupling, an interconnection structure, the interdependence of components, and synchronization between components. The degree of coupling refers to a measure that determines closely the processing elements are connected together. This can be measured as the ratio of the amount of data exchanged to the amount of local processing performed in executing a task. If the communication is done a computer network, there exits weak coupling among the processing elements. However, if components are shared we talk about strong coupling. Shared components can be both primary memory or secondary storage devices. As for the interconnection structure, one can talk about those case that has a point to point interconnection channel. The processing elements might depend on each other quite strongly in the execution of a task, or this interdependence might be as minimal as passing message at the beginning of execution and reporting results at the end. Synchronization between processing elements might be maintained by synchronous or by asynchronous means. Note that some of these criteria are not entirely independent of the processing elements to be strongly interdependent and possibly to work in a strongly coupled fashion.
Learn, Explaining the Different types of Data Mining Model!
Data Mining Models: Basically The data mining model are of two types. First Predictive and, Descriptive. Also learn, How to explain Organizational Culture? Meaning and Definition!
Descriptive Models: The descriptive model identifies the patterns or relationships in data and explores the properties of the data examined. Ex. Clustering, Summarization, Association rule, Sequence discovery etc. Clustering is similar to classification except that the groups are not predefined, but are defined by the data alone. It is also referred to as unsupervised learning or segmentation. It is the partitioning or segmentation of the data in to groups or clusters. The clusters are defined by studying the behavior of the data by the domain experts.
The term segmentation is used in very specific context; it is a process of partitioning of database into disjoint grouping of similar tuples. Summarization is the technique of presenting the summarize information from the data. The association rule finds the association between the different attributes. Association rule mining is a two step process: Finding all frequent item sets, Generating strong association rules from the frequent item sets. Sequence discovery is a process of finding the sequence patterns in data. This sequence can be used to understand the trend.
Predictive Models: The predictive model makes prediction about unknown data values by using the known values. Ex. Classification, Regression, Time series analysis, Prediction etc. Many of the data mining applications are aimed to predict the future state of the data. Prediction is the process of analyzing the current and past states of the attribute and prediction of its future state. Classification is a technique of mapping the target data to the predefined groups or classes, this is a supervise learning because the classes are predefined before the examination of the target data.
The regression involves the learning of function that map data item to real valued prediction variable. In the time series analysis the value of an attribute is examined as it varies over time. In time series analysis the distance measures are used to determine the similarity between different time series, the structure of the line is examined to determine its behavior and the historical time series plot is used to predict future values of the variable.
Model Types Used by Data Mining Technologies
The following represents a sampling of the types of modeling efforts possible using Nuggets the Data Mining Toolkit offered by Data Mining Technologies for the banking and Insurance Industries. Many other model types are used and we would be happy to discuss them in more detail if you contact us. Don’t forget to read it, The Importance Benefits of Corporate Retreats in Business!
Claims Fraud Models
The number of challenges facing the Property and Casualty insurance industry seems to have grown geometrically during the past decade. In the past, poor underwriting results and high loss ratio were compensated by excellent returns on investments. However, the performance of financial markets today is not sufficient to deliver the level of profitability that is necessary to support the traditional insurance business model. In order to survive in the bleak economic conditions that dictate the terms of today’s merciless and competitive market, insurers must change the way they operate to improve their underwriting results and profitability.
An important element in the process of defining the strategies that are essential to ensure the success and profitable results of insurers is the ability to forecast the new directions in which claims management should be developed. This endeavor has become a crucial and challenging undertaking for the insurance industry, given the dramatic events of the past years in the insurance industry worldwide. We can check claims as they arrive and score them as to the likelihood of they are fraudulent. This can results in large savings to the insurance companies that use these technologies.
Customer Clone Models
The process for selectively targeting prospects for your acquisition efforts often utilizes a sophisticated analytical technique called “best customer cloning.” These models estimate which prospects are most likely to respond based on characteristics of the company’s “best customers”. To this end, we build the models or demographic profiles that allow you to select only the best prospects or “clones” for your acquisition programs. In a retail environment, we can even identify the best prospects that are close in proximity to your stores or distribution channels. Customer clone models are appropriate when insufficient response data is available, providing an effective prospect ranking mechanism when response models cannot be built.
Response Models
The best method for identifying the customers or prospects to target for a specific product offering is through the use of a model developed specifically to predict response. These models are used to identify the customers most likely to exhibit the behavior being targeted. Predictive response models allow organizations to find the patterns that separate their customer base so the organization can contact those customers or prospects most likely to take the desired action. These models contribute to more effective marketing by ranking the best candidates for a specific product offering thus identifying the low hanging fruit.
Revenue and Profit Predictive Models
Revenue and Profit Prediction models combine response/non-response likelihood with a revenue estimate, especially if order sizes, monthly billings, or margins differ widely. Not all responses have equal value, and a model that maximizes responses doesn’t necessarily maximize revenue or profit. Revenue and profit predictive models indicate those respondents who are most likely to add a higher revenue or profit margin with their response than other responders.
These models use a scoring algorithm specifically calibrated to select revenue-producing customers and help identify the key characteristics that best identify better customers. They can be used to fine-tune standard response models or used in acquisition strategies.
Cross-Sell and Up-Sell Models
Cross-sell/up-sell models identify customers who are the best prospects for the purchase of additional products and services and for upgrading their existing products and services. The goal is to increase share of wallet. Revenue can increase immediately, but loyalty is enhanced as well due to increased customer involvement.
Attrition Models
Efficient, effective retention programs are critical in today’s competitive environment. While it is true that it is less costly to retain an existing customer than to acquire a new one, the fact is that all customers are not created equal. Attrition models enable you to identify customers who are likely to churn or switch to other providers thus allowing you to take appropriate preemptive action. When planning retention programs, it is essential to be able to identify best customers, how to optimize existing customers and how to build loyalty through “entanglement”. Attrition models are best employed when there are specific actions that the client can take to retard cancellation or cause the customer to become substantially more committed. The modeling technique provides an effective method for companies to identify characteristics of chumers for acquisition efforts and also to prevent or forestall cancellation of customers.
Marketing Effectiveness Creative Models
Often the message that is passed on to the customer is the one of the most important factors in the success of a campaign. Models can be developed to target each customer or prospect with the most effective message. In direct mail campaigns, this approach can be combined with response modeling to score each prospect with the likelihood they will respond given that they are given the most effective creative message (i.e. the one that is recommended by the model). In email campaigns this approach can be used to specify a customized creative message for each recipient.
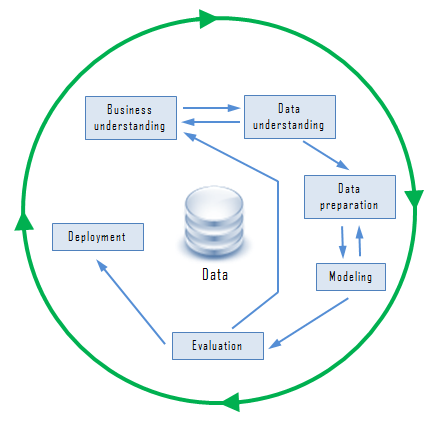
The Cross-Industry Standard Process for Data Mining (CRISP-DM) is the dominant data-mining process framework. It’s an open standard; anyone may use it. The following list describes the various phases of the process.
The Cross-Industry Standard Process for Data Mining
Business understanding
In the business understanding phase:
First, it is required to understand business objectives clearly and find out what are the business’s needs.
Next, we have to assess the current situation by finding of the resources, assumptions, constraints and other important factors which should be considered.
Then, from the business objectives and current situations, we need to create data mining goals to achieve the business objectives within the current situation.
Finally, a good data mining plan has to be established to achieve both business and data mining goals. The plan should be as detailed as possible.
Data understanding
First, the data understanding phase starts with initial data collection, which we collect from available data sources, to help us get familiar with the data. Some important activities must be performed including data load and data integration in order to make the data collection successfully.
Next, the “gross” or “surface” properties of acquired data need to be examined carefully and reported.
Then, the data needs to be explored by tackling the data mining questions, which can be addressed using querying, reporting, and visualization.
Finally, the data quality must be examined by answering some important questions such as “Is the acquired data complete?”, “Is there any missing values in the acquired data?”
Data preparation
The data preparation typically consumes about 90% of the time of the project. The outcome of the data preparation phase is the final data set. Once available data sources are identified, they need to be selected, cleaned, constructed and formatted into the desired form. The data exploration task at a greater depth may be carried during this phase to notice the patterns based on business understanding.
Modeling
First, modeling techniques have to be selected to be used for the prepared dataset.
Next, the test scenario must be generated to validate the quality and validity of the model.
Then, one or more models are created by running the modeling tool on the prepared dataset.
Finally, models need to be assessed carefully involving stakeholders to make sure that created models are met business initiatives.
Evaluation
In the evaluation phase, the model results must be evaluated in the context of business objectives in the first phase. In this phase, new business requirements may be raised due to the new patterns that have been discovered in the model results or from other factors. Gaining business understanding is an iterative process in data mining. The go or no-go decision must be made in this step to move to the deployment phase.
Deployment
The knowledge or information, which we gain through data mining process, needs to be presented in such a way that stakeholders can use it when they want it. Based on the business requirements, the deployment phase could be as simple as creating a report or as complex as a repeatable data mining process across the organization. In the deployment phase, the plans for deployment, maintenance, and monitoring have to be created for implementation and also future supports. From the project point of view, the final report of the project needs to summary the project experiences and review the project to see what need to improved created learned lessons.
The CRISP-DM offers a uniform framework for experience documentation and guidelines. In addition, the CRISP-DM can apply in various industries with different types of data.
In this article, you have learned about the data mining processes and examined the cross-industry standard process for data mining.
Something is not Forgetting What? Data mining is a promising and relatively new technology. Data mining is defined as a process of discovering hidden valuable knowledge by analyzing large amounts of data, which is stored in databases or data warehouse, using various data mining techniques such as machine learning, artificial intelligence(AI) and statistical.
Many organizations in various industries are taking advantages of data mining including manufacturing, marketing, chemical, aerospace… etc, to increase their business efficiency. Therefore, the needs for a standard data mining process increased dramatically. A data mining process must be reliable and it must be repeatable by business people with little or no knowledge of data mining background. As the result, in 1990, a cross-industry standard process for data mining (CRISP-DM) first published after going through a lot of workshops, and contributions from over 300 organizations.
Data mining is a promising and relatively new technology. Data mining is defined as a process of discovering hidden valuable knowledge by analyzing large amounts of data, which is stored in databases or data warehouse, using various data mining techniques such as machine learning, artificial intelligence(AI) and statistical.
Many organizations in various industries are taking advantages of data mining including manufacturing, marketing, chemical, aerospace… etc, to increase their business efficiency. Therefore, the needs for a standard data mining process increased dramatically. A data mining process must be reliable and it must be repeatable by business people with little or no knowledge of data mining background. As the result, in 1990, a cross-industry standard process for data mining (CRISP-DM) first published after going through a lot of workshops, and contributions from over 300 organizations.
The data mining process involves much hard work, including perhaps building data warehouse if the enterprise does not have one. A typical data mining process is likely to include the following steps:
Requirements analysis: The enterprise decision makers need to formulate goals that the data mining process is expected to achieve. The business problem must be clearly defined. One cannot use data mining without a good idea of what kind of outcomes the enterprise is looking for, since the technique to be used and the data that is required are likely to be different for different goals. Furthermore, if the objectives have been clearly defined, it is easier to evaluate the results of the project. Once the goals have been agreed upon, the following further steps are needed.
Data selection and collection: This step may include finding the best source databases for the data that is required. If the enterprise has implemented a data warehouse, then most of the data could be available there. If the data is not available in the warehouse or the enterprise does not have a warehouse, the source OLTP (On-line Transaction Processing) systems need to be identified and the required information extracted and stored in some temporary system. In some cases, only a sample of the data available may be required.
Cleaning and preparing data: This may not be an onerous task if a data warehouse containing the required . data exists, since most of this must have already been done when data was loaded in the warehouse. Otherwise this task can be very resource intensive and sometimes more than 50% of effort in a data mining project is spent on this step. Essentially a data store that integrates data from a number of databases may need to be created. When integrating data, one often encounters problems like identifying data, dealing with missing data, data conflicts and ambiguity. An ETL (extraction, transformation and loading) tool may be used to overcome these problems.
Data mining exploration and validation: Once appropriate data has been collected and cleaned, it is possible to start data mining exploration. Assuming that the user has access to one or more data mining tools, a data mining model may be constructed based on the enterprise’s needs. It may be possible to take a sample of data and apply a number of relevant techniques. For each technique the results should be evaluated and their significance interpreted. This is likely to be an iterative process which should lead to selection of one or more techniques that are suitable for further exploration, testing, and validation.
Implementing, evaluating, and monitoring: Once a model has been selected and validated, the model can be implemented for use by the decision makers. This may involve software development for generating reports, or for results visualization and explanation for managers. It may be that more than one technique is available for the given data mining task. It is then important to evaluate the results and choose the best technique. Evaluation may involve checking the accuracy and effectiveness of the technique. Furthermore, there is a need for regular monitoring of the performance of the techniques that have been implemented. It is essential that use of the tools by the managers be monitored and results evaluated regularly. Every enterprise evolves with time and so must the data mining system. Therefore, monitoring is likely to lead from time to time to refinement of tools and techniques that have been implemented.
Results visualization: Explaining the results of data mining to the decision makers is an important step of the data mining process. Most commercial data mining tools include data visualization modules. These tools are often vital in communicating the data mining results to the managers, although a problem dealing with a number of dimensions must be visualized using a two dimensional computer screen or printout. Clever data visualization tools are being developed to display results that deal with more than two dimensions. The visualization tools available should be tried and used if found effective for the given problem.
Data mining functionalities are used to specify the kind of patterns to be found in data mining tasks. The Different types of Data Mining Functionalities.
Data mining has an important place in today’s world. It becomes an important research area as there is a huge amount of data available in most of the applications. Data mining functionalities are used to specify the kind of patterns to be found in data mining tasks. Data mining tasks can be classified into two categories: descriptive and predictive. First Descriptive mining – tasks characterize the general properties of the data in the database, and second Predictive mining – tasks perform inference on the current data in order to make predictions. You’ll be studying The Different types of Data Mining Functionalities.
This huge amount of data must be processed in order to extract useful information and knowledge since they are not explicit. Data Mining is the process of discovering interesting knowledge from a large amount of data. The kinds of patterns that can be discovered depend upon the data mining tasks employed. By and large, there are two types of data mining tasks: descriptive data mining tasks that describe the general properties of the existing data, and predictive data mining tasks that attempt to do predictions based on inference on available data.
The data mining functionalities and the variety of knowledge they discover are briefly presented in the following list:
Characterization: It is the summarization of general features of objects in a target class, and produces what is called characteristic rules. The data relevant to a user-specified class are normally retrieved by a database query and run through a summarization module to extract the essence of the data at different levels of abstractions.
For example, one may wish to characterize the customers of a store who regularly rent more than movies a year. With concept hierarchies on the attributes describing the target class, the attribute-oriented induction method can be used to carry out data summarization. With a data cube containing summarization of data, simple OLAP operations fit the purpose of data characterization.
Discrimination: Data discrimination produces what are called discriminant rules and is basically the comparison of the general features of objects between two classes referred to as the target class and the contrasting class.
For example, one may wish to compare the general characteristics of the customers who rented more than 30 movies in the last year with those whose rental account is lower than. The techniques used for data discrimination are similar to the techniques used for data characterization with the exception that data discrimination results include comparative measures.
Association analysis: Association analysis studies the frequency of items occurring together in transactional databases, and based on a threshold called support, identifies the frequent itemsets. Another threshold, confidence, which is the conditional probability that an item appears in a transaction when another item appears, is used to pinpoint association rules. This is commonly used for market basket analysis.
For example, it could be useful for the manager to know what movies are often rented together or if there is a relationship between renting a certain type of movies and buying popcorn or pop. The discovered association rules are of the form: P→Q [s, c], where P and Q are conjunctions of attribute value-pairs, and s (support) is the probability that P and Q appear together in a transaction and c (confidence) is the conditional probability that Q appears in a transaction when P is present. For example, Rent Type (X,“game”)∧Age(X,“13-19”)→Buys(X,“pop”)[s=2%, =55%] The above rule would indicate that 2% of the transactions considered are of customers aged between 13 and 19 who are renting a game and buying a pop, and that there is a certainty of 55% that teenage customers who rent a game also buy pop.
Classification: It is the organization of data in given classes. Classification uses given class labels to order the objects in the data collection. Classification approaches normally use a training set where all objects are already associated with known class labels. The classification algorithm learns from the training set and builds a model. The model is used to classify new objects.
For example, after starting a credit policy, the manager of a store could analyze the customers’ behavior vis-à-vis their credit, and label accordingly the customers who received credits with three possible labels “safe”, “risky” and “very risky”. The classification analysis would generate a model that could be used to either accept or reject credit requests in the future.
Prediction: Prediction has attracted considerable attention given the potential implications of successful forecasting in a business context. There are two major 50 types of predictions; one can either try to predict some unavailable data values or pending trends or predict a class label for some data. The latter is tied to classification. Once a classification model is built based on a training set, the class label of an object can be foreseen based on the attribute values of the object and the attribute values of the classes. Prediction is, however, more often referred to the forecast of missing numerical values, or increase/ decrease trends in time-related data. The major idea is to use a large number of past values to consider probable future values.
Clustering: Similar to classification, clustering is the organization of data in classes. However, unlike classification, in clustering, class labels are unknown and it is up to the clustering algorithm to discover acceptable classes. Clustering is also called unsupervised classification because the classification is not dictated by given class labels. There are many clustering approaches all based on the principle of maximizing the similarity between objects in the same class (intra-class similarity) and minimizing the similarity between objects of different classes (inter-class similarity).
Outlier analysis: Outliers are data elements that cannot be grouped in a given class or cluster. Also known as exceptions or surprises, they are often very important to identify. While outliers can be considered noise and discarded in some applications, they can reveal important knowledge in other domains, and thus can be very significant and their analysis valuable.
Evolution and deviation analysis: Evolution and deviation analysis pertain to the study of time-related data that changes in time. Evolution analysis models evolutionary trends in data, which consent to characterize, comparing, classifying or clustering of time-related data. Deviation analysis, on the other hand, considers differences between measured values and expected values, and attempts to find the cause of the deviations from the anticipated values.
It is common that users do not have a clear idea of the kind of patterns they can discover or need to discover from the data at hand. It is therefore important to have a versatile and inclusive data mining system that allows the discovery of different kinds of knowledge and at different levels of abstraction. This also makes interactivity an important attribute of a data mining system.
Data mining involves the use of sophisticated data analysis tools to discover previously unknown, valid patterns and relationships in large data sets. These tools can include statistical models, mathematical algorithms, and machine learning methods such as neural networks or decision trees. Consequently, data mining consists of more than collecting and managing data, it also includes analysis and prediction. The objective of data mining is to identify valid, novel, potentially useful, and understandable correlations and patterns in existing data. Finding useful patterns in data is known by different names (e.g., knowledge extraction, information discovery, information harvesting, data archaeology, and data pattern processing).
The term “data mining” is primarily used by statisticians, database researchers, and the business communities. The term KDD (Knowledge Discovery in Databases) refers to the overall process of discovering useful knowledge from data, where data mining is a particular step in this process. The steps in the KDD process, such as data preparation, data selection, data cleaning, and proper interpretation of the results of the data mining process, ensure that useful knowledge is derived from the data. Data mining is an extension of traditional data analysis and statistical approaches as it incorporates analytical techniques drawn from various disciplines like AI, machine learning, OLAP, data visualization, etc.
Data Mining covers variety of techniques to identify nuggets of information or decision-making knowledge in bodies of data, and extracting these in such a way that they can be. Put to use in the areas such as decision support, prediction, forecasting and estimation. The data is often voluminous, but as it stands of low value as no direct use can be made of it; it is the hidden information in the data that is really useful. Data mining encompasses a number of different technical approaches, such as clustering, data summarization, learning classification rules, finding dependency net works, analyzing changes, and detecting anomalies. Data mining is the analysis of data and the use of software techniques for finding patterns and regularities in sets of data. The computer is responsible for finding the patterns by identifying the underlying rules and features in the data. It is possible to ‘strike gold’ in unexpected places as the data mining software extracts patterns not previously discernible or so obvious that no-one has noticed them before. In Data Mining, large volumes of data are sifted in an attempt to find something worthwhile.
Data mining plays a leading role in the every facet of Business. It is one of the ways by which a company can gain competitive advantage. Through application of Data mining, one can tum large volumes of data collected from various front-end systems like Transaction Processing Systems, ERP, and operational CRM into meaningful knowledge.
“Data mining is the computing process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. It is an interdisciplinary subfield of computer science. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Aside from the raw analysis step, it involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating. Data mining is the analysis step of the “knowledge discovery in databases” process, or KDD.”
Data Mining History and Current Advances
The process of digging through data to discover hidden connections and predict future trends has a long history. Sometimes referred to as “knowledge discovery in databases,” the term “data mining” wasn’t coined until the 1990s. But its foundation comprises three intertwined scientific disciplines: statistics (the numeric study of data relationships), artificial intelligence (human-like intelligence displayed by software and/or machines) and machine learning (algorithms that can learn from data to make predictions). What was old is new again, as data mining technology keeps evolving to keep pace with the limitless potential of big data and affordable computing power.
Over the last decade, advances in processing power and speed have enabled us to move beyond manual, tedious and time-consuming practices to quick, easy and automated data analysis. The more complex the data sets collected, the more potential there is to uncover relevant insights. Retailers, banks, manufacturers, telecommunications providers and insurers, among others, are using data mining to discover relationships among everything from pricing, promotions and demographics to how the economy, risk, competition and social media are affecting their business models, revenues, operations and customer relationships.
Who’s using it?
Data mining is at the heart of analytics efforts across a variety of industries and disciplines.
Communications: In an overloaded market where competition is tight, the answers are often within your consumer data. Multimedia and telecommunications companies can use analytic models to make sense of mountains of customers data, helping them predict customer behavior and offer highly targeted and relevant campaigns.
Insurance: With analytic know-how, insurance companies can solve complex problems concerning fraud, compliance, risk management and customer attrition. Companies have used data mining techniques to price products more effectively across business lines and find new ways to offer competitive products to their existing customer base.
Education: With unified, data-driven views of student progress, educators can predict student performance before they set foot in the classroom – and develop intervention strategies to keep them on course. Data mining helps educators access student data, predict achievement levels and pinpoint students or groups of students in need of extra attention.
Manufacturing: Aligning supply plans with demand forecasts is essential, as is early detection of problems, quality assurance and investment in brand equity. Manufacturers can predict wear of production assets and anticipate maintenance, which can maximize uptime and keep the production line on schedule.
Banking: Automated algorithms help banks understand their customer base as well as the billions of transactions at the heart of the financial system. Data mining helps financial services companies get a better view of market risks, detect fraud faster, manage regulatory compliance obligations and get optimal returns on their marketing investments.
Retail: Large customer databases hold hidden insights that can help you improve customer relationships, optimize marketing campaigns and forecast sales. Through more accurate data models, retail companies can offer more targeted campaigns – and find the offer that makes the biggest impact on the customer.