What is Phases of the Data Mining Process?
The Cross-Industry Standard Process for Data Mining (CRISP-DM) is the dominant data-mining process framework. It’s an open standard; anyone may use it. The following list describes the various phases of the process.
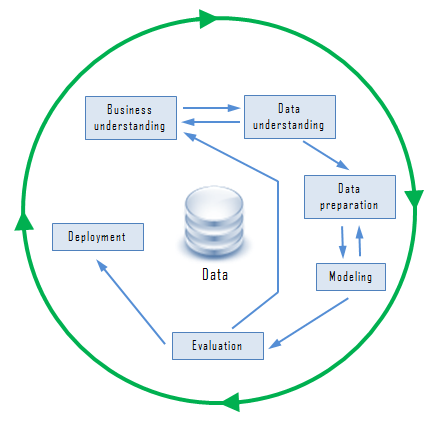
Business understanding
In the business understanding phase:
First, it is required to understand business objectives clearly and find out what are the business’s needs.
Next, we have to assess the current situation by finding of the resources, assumptions, constraints and other important factors which should be considered.
Then, from the business objectives and current situations, we need to create data mining goals to achieve the business objectives within the current situation.
Finally, a good data mining plan has to be established to achieve both business and data mining goals. The plan should be as detailed as possible.
Data understanding
First, the data understanding phase starts with initial data collection, which we collect from available data sources, to help us get familiar with the data. Some important activities must be performed including data load and data integration in order to make the data collection successfully.
Next, the “gross” or “surface” properties of acquired data need to be examined carefully and reported.
Then, the data needs to be explored by tackling the data mining questions, which can be addressed using querying, reporting, and visualization.
Finally, the data quality must be examined by answering some important questions such as “Is the acquired data complete?”, “Is there any missing values in the acquired data?”
Data preparation
The data preparation typically consumes about 90% of the time of the project. The outcome of the data preparation phase is the final data set. Once available data sources are identified, they need to be selected, cleaned, constructed and formatted into the desired form. The data exploration task at a greater depth may be carried during this phase to notice the patterns based on business understanding.
Modeling
First, modeling techniques have to be selected to be used for the prepared dataset.
Next, the test scenario must be generated to validate the quality and validity of the model.
Then, one or more models are created by running the modeling tool on the prepared dataset.
Finally, models need to be assessed carefully involving stakeholders to make sure that created models are met business initiatives.
Evaluation
In the evaluation phase, the model results must be evaluated in the context of business objectives in the first phase. In this phase, new business requirements may be raised due to the new patterns that have been discovered in the model results or from other factors. Gaining business understanding is an iterative process in data mining. The go or no-go decision must be made in this step to move to the deployment phase.
Deployment
The knowledge or information, which we gain through data mining process, needs to be presented in such a way that stakeholders can use it when they want it. Based on the business requirements, the deployment phase could be as simple as creating a report or as complex as a repeatable data mining process across the organization. In the deployment phase, the plans for deployment, maintenance, and monitoring have to be created for implementation and also future supports. From the project point of view, the final report of the project needs to summary the project experiences and review the project to see what need to improved created learned lessons.
The CRISP-DM offers a uniform framework for experience documentation and guidelines. In addition, the CRISP-DM can apply in various industries with different types of data.
In this article, you have learned about the data mining processes and examined the cross-industry standard process for data mining.
Something is not Forgetting What? Data mining is a promising and relatively new technology. Data mining is defined as a process of discovering hidden valuable knowledge by analyzing large amounts of data, which is stored in databases or data warehouse, using various data mining techniques such as machine learning, artificial intelligence(AI) and statistical.
Many organizations in various industries are taking advantages of data mining including manufacturing, marketing, chemical, aerospace… etc, to increase their business efficiency. Therefore, the needs for a standard data mining process increased dramatically. A data mining process must be reliable and it must be repeatable by business people with little or no knowledge of data mining background. As the result, in 1990, a cross-industry standard process for data mining (CRISP-DM) first published after going through a lot of workshops, and contributions from over 300 organizations.







